 영상
영상
브리태니카 백과사전은 빅데이터 보고
1980년대 필자가 고등학생 때 같은 반 친구의 집 중에서 ‘브리태니커(Britannica) 백과사전’ 전집이 있는 학생이 있었다. 그 브리태니커 백과사전은 1768년에 영국에서 처음 발간되었고, 현재까지 이어져 오는 백과사전들 중 가장 오래되었다. 이 사전에 등재되어 있는 항목만도 12만 개가 넘으며, 원본의 단어를 이루고 있는 개수가 무려 4400만 개이다. 그러나 인터넷이 발전하면서 그 영향력이 감소하였고, 마침내 인쇄본의 생산중단이 결정되었다.
그 때 브리태니커 백과사전은 미국 중산층 서재의 필수요소였고 한국에서는 경제적 여유가 있고 자녀의 교육에 관심이 높은 일부 가구에 보급되었다. 가정에서의 지적 관심과 지원의 상징이었다. 방대한 분량의 백과사전으로 영어로 되어 있었고, 그림이 아주 자세히 있었던 기억이 난다. 반면 필자의 집에는 두께만 10센티 되어 보이는 ‘의학 대 백과사전’이 있었다. 가끔 열어 보고 훑어 보면서 시간을 보낸 기억이 난다. 이렇게 백과사전은 가정에서 혹은 도서관에서 자료에 대한 조사와 공부도 되고 무심결에 열어 보면서 어떤 분야에 상식이 생기고 새로운 분야에 관심이 가기도 한다. 백과사전은 지적 호기심의 자극제였다. 지금은 두꺼운 전집인 백과사전을 인터넷 검색기, 네어버, 구글, 위키디피아가 이를 대체하고 있다.
다르게 보면 백과사전이 바로 ‘빅데이터’이다. 인류의 유산과 지식이 여기에 담겨있는 바야흐로 빅데이터의 보고이다. 문자가 발명되고, 활자가 보급되면서 급속히 많은 빅데이터가 책으로 축적되었다. ‘성경’과 ‘불경’도 여기에 포함된다. 이런 문자와 책으로 표현된 빅데이터로 인공지능이 학습을 한다면 인공지능의 성능이 한층 더 향상되고 정밀해 진다. 더 똑똑해 진다. 특히 책 속의 빅데이터가 디지털화되면 송신, 저장, 프로세스가 쉽게 된다. 당연히 인공지능 알고리즘으로 처리가 되고, 입력이 되고, 출력이 된다. 지금은 인공지능이 주로 인터넷에 올라온 사진과 동영상과 텍스트로로 학습을 하지만 미래에는 인류 역사상 가장 큰 축적물인, 바로 책으로 학습을 할 날이 곧 올 수도 있다.
세종대왕과 인공지능
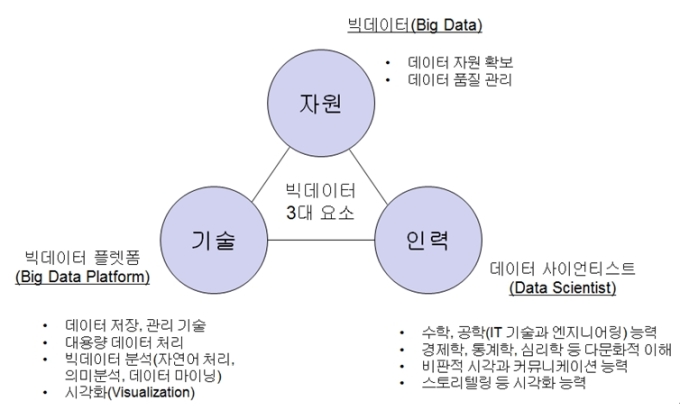
고려 시대부터 시작한 ‘과거 제도’는 관리의 임명제도이다. 공평한 선발 시험을 통해 우수한 ‘신하’를 구하기 위한 자원을 확보한다는 의도의 제도이다. 하지만 한편으로는 한문으로 시험을 본다는 것은 중국어의 소통 능력과 문서 작성 능력을 시험하는 제도라고 볼 수 있다. 조선의 국가 이념인 성리학 수준을 테스트했다는 의도도 같이 있다. 하지만 백성에서 듣고 읽고, 쓸 수 있는 문자를 발명한 ‘한글의 방명’은 우리 역사상 가장 중요하고 대단한 업적이다. 이렇게 세종대왕이 발명한 ‘한글’은 백성들에게 문맹을 퇴치한다는 백성을 사랑하는 ‘애민’ 정신이 깃들어 있다.
1446년 조선시대 세종대왕이 ‘한글’을 새로 창제해 반포하고 훈민정음을 발간했다. 이때 훈민정음은 크게 '예의'와 '해례'로 나누어져 있다. 최근 ‘해례” 상주본 소장자가 "1천억원을 받으면 국가에 헌납하겠다"는 뜻을 밝혀 논란이 됐다. 이러한 소동과는 별개로 ‘한글’은 4차 산업혁명 시대의 ‘빅데이터 보물 창고’로 재 발견되고 있다. 한글이 없으면 우리 고유의 문자도 없고, 빅데이터도 없고, 문화 자주권도 없다. 600년 전에 한글을 창제할 때, 빅데이터와 인공지능 시대를 예감하기는 어려웠다. 만약 훈민정음 해례 상주본에서 빅데이터나 인공지능이 언급되어 있다면 그 가치는 1천억원이 아니라 수백 조원을 불러도 아깝지 않은 문화재가 되었을 것이다.
훈민정음은 오늘날 4차 산업혁명 시대의 관점에서 보면 빅데이터이고, ‘한글’은 우리말 빅데이터가 가능하게 한 원천이다. 이렇게 한글은 ‘한글 기반 빅데이터’ 의 가능성을 만들었다. 세종대왕이 한글 기반 빅데이터 시대를 준비했다고 이야기를 하고 싶다. 한글이 있어서 스마트폰 입력이 되고, 컴퓨터 자판이 생기고 그 결과 우리가 매일 매순간 쓰고 있는 문자, 텍스트, 작품, 책 전체가 디지털로 변환되고, 그 결과 우리 정신의 축적물인 한글 빅데이터의 축적이 가능하다. 세종대왕이 다시 한번 우리를 위해 배려하고 있는 것이다. 그것도 4차 산업혁명 시대에 더욱 그렇다.
빌게이츠가 생각한 빅데이터
마이크로소프트를 창업한 빌게이츠가 최근에 창업에 대해서 말한 적이 있다. 빌 게이츠는 만약 오늘 자신이 새 회사를 차린다면 컴퓨터에 읽는 법을 알려주는 인공지능(AI) 회사를 할 것이라고 밝혔다. 다시 말해 ‘책을 읽는 인공지능 기계’를 창업하고 싶다고 한다. CNBC 등 주요 외신에 따르면 빌 게이츠는 워싱턴에서 열린 ‘워싱턴 경제 클럽’ 행사에서 이같이 언급했다고 한다. 그는 “내 배경을 고려할 때 나는 컴퓨터에 읽는 법을 가르치는 것이 목표인 AI 회사를 시작할 것”이라며 “그러면 그 컴퓨터는 이 세계의 모든 기록된 지식을 흡수하고 이해할 수 있을 것”이라고 말했다. 빌 게이츠는 이어 “이 분야는 AI가 아직 진전을 이루지 못한 영역”이라며 “우리가 그 목표를 달성하면 파급효과는 굉장할 것”이라고 덧붙였다.

이 의미는 빌 게이츠는 인류의 유사이래 축적한 책에 담겨져 있는 빅데이터의 가능성을 높게 평가한 것이다. 민일 우리가 미래에 전세게 도서관에 보관된 수 백가지 언어로 표현된 책 모두 읽어 들이고, 디지털화 하고, 저장해서 빅데이터로 만들고, 결국 이를 인공지능 학습을 위한 빅데이터로 입력으로 한다면 인공지능 컴퓨터는 완전히 모든 분야에서 ‘천재 인공지능’으로 탄생한다.
이렇게 인공지능 컴퓨터가 책을 읽기 위해서는 책 각각 한 페이지씩 사진으로 읽거나, 스캔해서 읽거나 하면서 한 장 한 장 넘기면서 읽고, 디지털 데이터 형식으로 저장해야 한다. 문제는 현재의 기술로 이러한 입력 작업에 시간이 너무 오래 걸릴 가능성이 높다. 빛의 속도로 빠르고, 방대한 분량을 처리하고, 값싼 책 읽기 기계가 필요하다. 책 한 권을 리더기 위에 놓으면 1밀리초 내에 모두 스캔할 수 있는 3차원 스캐너가 필요하다. 혹은 도서관 서가 전체를 1초에 스캔하며 더 좋다. 사진이나 영상은 스마트폰이 이러한 난관을 해결해 주었다. 이러한 기능을 가진 기계가 등장하면 완전 또 다른 빅데이터를 얻게 되고, 4차 산업혁명과 인공지능 시대가 한 단계 더 나아가게 된다. 이렇게 새로운 빅데이터를 확보하기 위해서는 신기술이 필요하다. 여기에 벤처 창업 기업이 탄생한다.
더 훗날 미래에 책 다음으로 인공지능을 위한 빅데이터의 원천은 아마 ‘인간의 뇌와 인체’가 된다. 그 인간의 뇌와 인체 속에 담긴 모든 인간의 데이터가 또 다른 값어치 높은 빅데이터가 된다. 그러려면 인간과 인간의 뇌를 읽는 기계가 필요하다. 책 읽는 인공지능 기계의 개발보다 더 긴 시간이 더 걸릴 전망이다.
2017년 5월 16일 마이크로소프트 창업자인 빌 게이츠가 14개의 시리즈 트윗을 통해 취업 준비생들한테 미래의 가능성에 대해서 조언을 했다. 그는 트윗에서 ‘’인공지능(AI), 에너지, 바이오 분야가 유망하다. 큰 임팩트를 만들 수 있다. 내가 오늘 대학을 나와 사회에 진출한다면 이런 분야에서 출발하겠다’ 라고 이야기 했다. 지금 인공지능을 시작해도 늦지 않는다.
[김정호 카이스트 전기 및 전자공학과 교수] joungho@kaist.ac.kr




