 영상
영상[서울=뉴스핌] 이서영 기자 = 정부가 3000억원 가량을 쏟아부은 'AI학습용 데이터구축' 사업이 시작부터 삐걱거리고 있다. 지난 9월 공모를 통해 584개에 이르는 기업과 기관으로부터 수집한 데이터 중 활용 불가한 '저품질 데이터'가 걸러지지 않았다는 지적이다.
이번 사업의 데이터 품질관리를 담당하는 스타트업 내부 관계자에 따르면 이번 과제에 선정된 참여 기업의 경우 몇백 억개 데이터를 모아야 하는데도 불구하고 기본 천여 개 정도 데이터만 모은 뒤, 복사와 붙여넣기 등의 방법으로 제출한 경우가 포착됐다. 또, 유명 데이터 셋인 MS코코(COCO, Common Object in COntext)나 구글 오픈 이미지 등의 해외 데이터를 그대로 가져온 경우도 더러 드러났다는 것.
'AI 학습용 데이터 구축' 사업은 한국정보화진흥원(NIA) 주관 아래 지난 9월부터 12월까지 진행중이다. 예산은 2925억원. 사업은 자연어·헬스케어·자율주행 등 150개 과제이며 참여 기업과 기관도 584개다. 다만 공모 선정기업들의 데이터에서 발견되는 '저품질' 이슈는 향후 관련사업 진행에 상당한 애로가 될 수 있다.
사실 '데이터 품질'은 AI 서비스의 신뢰성과 안정성으로 이어진다. 사업을 주관하는 NIA가 발간한 'AI 학습용 데이터 사업의 실효성 향상을 위한 정책 방향' 보고서에 따르면 아주 작은 실수로도 실제 쓸 수 없는 정밀도가 나오는 경우가 많아 성능적 측면에서 품질 관리는 상당히 중요하다.
다시말해, 유사 데이터를 그대로 복사·붙여넣기 하는 경우 AI로 활용되기 어렵다는 의미다. 또 해외 데이터인 코코나 구글 오픈 이미지의 데이터를 그대로 가져오는 것 역시 의미가 없다. 해당 정보는 이미 오픈돼 벌써 활용되고 있기 때문이다.
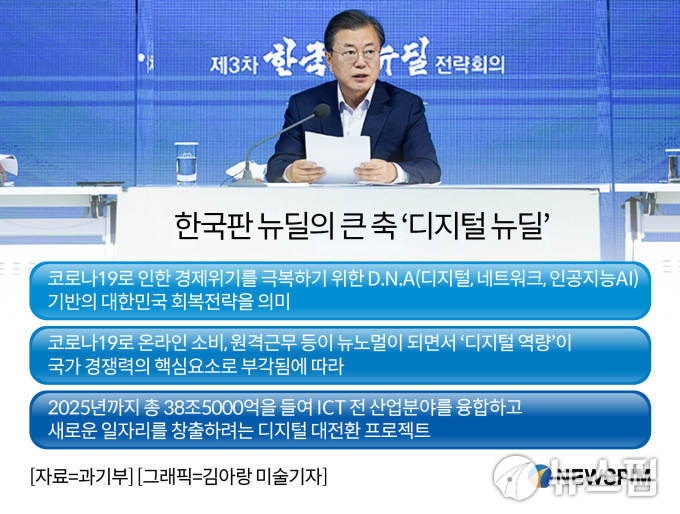
특히 'AI 학습용 데이터 구축 사업'은 정부가 제시한 '디지털 뉴딜'의 핵심 토대가 되는 사업이다. '디지털 뉴딜'을 위해 2025년까지 D·N·A(데이터, 네트워크, AI) 생태계를 만들어야 하고, 이를 위해선 생태계가 제대로 작동하도록 하는 '데이터 구축'이 필수. 정부는 앞서 2025년까지 D·N·A 기반 생태계를 만들기 위해 총 38조5000억 투입 계획을 밝히기도 했다.
AI MY뉴스 AI 추천


이에 대해 NIA 측은 "품질이 안 좋다고 말한 곳이 어디인지 모르겠지만 전체 150종 데이터를 다루는데 품질이 좋지 않은 일부가 있을 수는 있다"면서 "다만 이것이 전체를 대표하는 것은 아니다"는 입장이다.
품질관리에도 만전을 기하고 있다고 강조했다. 품질관리를 맡은 한국정보통신기술협회(TTA)측 AI 담당자는 "사업 기간이 짧은데 비해 종류는 150종이다보니 저품질 데이터가 생산될 수는 있다"면서도 "그래도 짧은 기간 동안 품질 검증을 해 오류를 개선하려고 노력 중"이라고 답했다.
그러면서 유사 데이터 등 저품질 데이터 문제에 대해 "간혹 작업자들 오류로 비슷한 데이터가 연달아 올라오는 경우도 있다고 듣긴 했다"며 "이에 같은 카테고리 내에서 유사 데이터가 20-30개 이상이 되지 않도록 가이드라인은 제시했다"고 했다.
jellyfish@newspim.com





