영상
영상
엔비디아 스토리
컴퓨터 구조에서 대표적으로 사용되는 반도체로는 계산 장치인 프로세서(Processor)와 메모리(Memory)가 있다. 그중에서 프로세서로는 개인용 컴퓨터에 많이 사용되는 CPU(Central Processing Unit)가 있고, 스마트폰에는 주로 AP(Application Processor)가 사용되고, 컴퓨터 그래픽 카드에는 GPU(Graphic Process Unit)가 사용된다.
이러한 프로세서 중에서 인공지능 계산을 위한 병렬처리에는 GPU가 가장 많이 사용된다. GPU 내부에는 계산기(Arithmetic Logic Unit, ALU) 코어의 개수가 수천 개 혹은 수만 개에 이른다. 그래서 동시 병렬 계산이 용이하다. 이러한 이유로 인공지능 계산에 GPU가 가장 유용한 프로세서가 된다.
이러한 배경으로 대표적인 GPU 회사인 엔비디아(NVidia)의 성장이 두드러진다. 최근에 GPU는 가상화폐 채굴에 쓰이기도 해서 한때 품절이 나기도 했다. 여기에 그치지 않고 자율주행 자동차의 인공지능 처리에도 GPU가 사용될 전망이다. 그 때문에 지난 10년간 엔비디아의 주가는 꾸준히 상승하고 있다. 이래저래 CPU, AP보다 GPU의 계속된 성장이 기대된다.

필자의 연구실에서는 지난 10여년간 GPU와 디램이 3차원적으로 결합한 HBM(High Bandwidth Memory) 모듈을 설계하는 연구를 진행해왔다. 그 과정에서 국내의 삼성전자, SK하이닉스뿐만 아니라 엔비디아와 협력을 지속해 왔다.
HBM에서는 기존의 모듈과는 달리 실리콘 기판을 배선으로 사용해 GPU와 디램 사이의 연결선 개수를 대폭으로 늘린다. 더 빨리 많은 수의 병저렬 계산을 하기 위해서 고안됐다. 이 HBM 모듈은 주로 인공지능 서버에 사용하고 있으며, 그 가격은 1000만원에 가깝다.
이렇게 비용이 많이 드는 것이 단점이지만, 인공지능 시대를 맞아 수요는 계속 증가할 것으로 생각한다. 이러한 이유로 필자의 연구실 졸업생이 엔비디아에 여러 명 진출했다. 대학원 학생들이 인턴으로도 엔비니아에 파견 나가기도 한다.

인공지능의 기본은 행렬 수학
인공지능에서 지능신경망인 DNN(Deep Neural Network)의 입력은 디지털 데이터이다. 그리고 데이터 입력은 일정 수의 데이터 묶음 형태로 표현된다. 이러한 디지털 데이터의 묶음을 수학 용어로 벡터(Vector)라고 한다.
예를 들어 카메라 이미지 화소점인 픽셀(Pixel) 하나에는 RGB(Red, Green, Blue) 세 가지 색깔의 배합과 밝기가 표현된다. 그러면 이미 4가지 요소를 갖는 벡터가 된다. 거기에 더해 화면 속의 위치 정보가 x, y로 들어가면 6열 벡터가 된다. 언어를 입력 벡터로 쓴다면 그 벡터 크기가 수백만개도 된다. 단어의 개수가 그만큼 많다.
이러한 입력 벡터를 다른 형태로 변환할 필요가 생긴다. 이때 벡터와 행렬(Matrix) 곱셈이 필요하다. 예를 들어 그래픽 처리에서 위치 정보가 포함된 벡터의 좌표를 변환하려고 한다면, 이 벡터에 행렬을 곱하면 된다.
보는 관찰자의 위치를 3차원으로 바꾼다면 새로운 좌표에서 다시 위치를 잡기 위해서 데이터 벡터에 좌표 변환을 하게 되는데, 이때 벡터에 좌표 변환 3x3 행렬을 곱하게 된다.
마찬가지로 인공지능 판단이나 예측에도 벡터와 행렬 계산이 사용된다. DNN에서는 입력이 데이터 벡터가 되고, 그 벡터 신호에 입력층(Input layer), 은닉층(Hidden layer), 출력층(Output layer)으로 지나가면서 계속 행렬 곱셈이 일어난다. 이러한 과정을 전전파 학습(Forward Propagation Training)이라고 한다.

거꾸로 최종 정답과의 차이를 확인하고 반대 방향으로 행렬을 곱해가면서 네트워크를 교정해 가는 과정을 역전파 학습(Backward Propagation Training)이라고 한다.
이처럼 학습과정에서 행렬계산이 수없이 일어난다. 그래서 인공지능 계산에서 가장 빈번히 일어나는 컴퓨터 계산이 행렬 곱셈과 덧셈이다. 그리고 이러한 병렬 계산에 GPU가 가장 적합한 프로세서 구조이다.

인공지능을 위한 GPU 구조
이와 같은 행렬 계산은 하나하나 순차적으로 일어나지 않고 동시에 병렬로 한다. 이렇게 동시에 병렬로 계산하는 방법으로는 컴퓨터를 병렬로 연결해서 수행하는 방법이 있다. 초기 구글 알파고에서 쓰인 방법이다.
그러나 이러한 병렬 계산을 위해서는 컴퓨터끼리 데이터를 주고받아야 한다. 컴퓨터끼리 케이블로 연결돼야 한다. 이러면 데이터를 컴퓨터 간에 이동하는 데 시간이 걸린다. GPU는 반도체 프로세서 내부에서 병렬 계산을 하므로 빠르고 효율적이다.
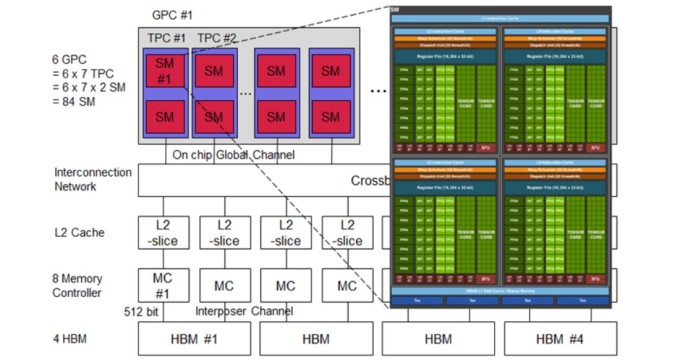
엔비디아 GPU의 경우, 내부에서 80여개의 SM(Streaming Multiprocessor)이 병렬 계산을 나누어서 한다. 그 SM 속에는 32개의 중간 크기의 계산블록(Warp)이 있고, 각 Warp에는 64개의 계산 코어(Thread)가 있다.
그래서 GPU 내에는 전체적으로 80x64x32=16만3840개의 병렬 계산 코어가 있다. 이들이 동시에 병렬 계산을 한다. 앞으로는 계산 코어의 개수가 100배 이상 증가할 것으로 예상한다. 모두 행렬 계산을 빠르고 효율적으로 하기 위함이다.
GPU에도 단점은 있다. 코어가 많기 때문에 코어 주변에 계산 결과를 임시로 저장하는 캐쉬(Cash) 메모리가 한정돼 있다. 그래서 매번 계산 결과를 낼 때마다 외부의 디램에 저장하고 다시 읽어 와야 하는 번거로움이 있다. GPU 외부 메모리인 디램의 성능이 지원해줘야 한다. GPU의 성능을 위해서는 디램의 성능도 같이 좋아져야 한다.
마지막으로 GPU의 어려운 점은 계산량이 너무 많아서 프로세서에서 열이 많이 발생하고, 그 결과 반도체 온도가 올라간다는 점이다. 그러면 프로세서의 계산 능력이 급속히 감소한다. 그래서 반도체 냉각 기술이 중요해지고 있다.
이처럼 GPU는 더욱 병렬화되고, 메모리와도 병렬화되며, 냉각 기술을 위한 혁신이 계속될 전망이다. 4차 산업혁명이 진행되면서 GPU의 수요와 기술 발전은 더욱 심화할 전망이다.
[김정호 카이스트 전기 및 전자공학과 교수] joungho@kaist.ac.kr