영상
영상[세종=뉴스핌] 이경태 기자 = 한국과학기술원(KAIST)은 전기및전자공학부 노용만 교수 연구팀이 오픈AI(OpenAI)의 GPT-4 등 기업에서 비공개하고 있는 상업 모델인 초대형 언어모델의 시각 성능을 뛰어넘는 공개형 멀티모달 대형 언어모델을 개발해 출시했다고 20일 밝혔다.
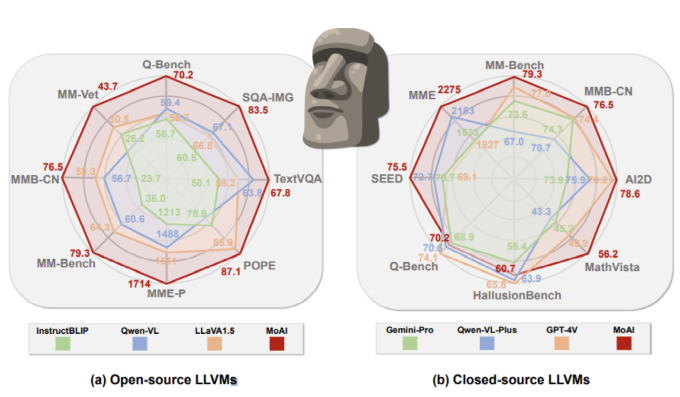
노용만 교수 연구팀은 단순히 모델의 크기를 키우거나 고품질의 시각적 지시 조정 데이터셋을 만들지 않고 멀티모달 대형언어모델의 시각 성능을 획기적으로 높인 콜라보(CoLLaVO), 모아이(MoAI) 2가지 기술을 연속적으로 개발했다.
연구팀이 개발한 첫번째 기술인 '콜라보(CoLLaVO)'는 현존하는 공개형 멀티모달 대형언어모델이 비공개형 모델의 성능에 비해 현저하게 낮은 이유를 일차적으로 물체 수준에 대한 이미지 이해 능력이 현저하게 떨어진다는 것을 먼저 검증했다.
해당 능력을 효율적으로 증가시켜 시각-언어 태스크에 대한 성능을 향상 하기 위해 연구팀은 이미지 내의 정보를 배경과 물체 단위로 분할하고 각 배경 및 물체에 대한 정보를 멀티모달 대형언어모델에 입력으로 직접 넣어주는 새로운 방법인 '크레용 프롬프트(Crayon Prompt)'라는 시각적 프롬프트를 새롭게 제안했다.
시각적 지시 조정 단계에서 크레용 프롬프트로 학습한 정보를 잃어버리지 않기 위해 연구팀은 물체 수준 이미지 이해 능력과 시각-언어 태스크 처리 능력을 서로 다른 파라미터로 학습해 서로 간의 정보를 잃지 않게 만드는 획기적인 학습 전략인 '듀얼 큐로라(Dual QLoRA)'를 제안했다.
연구팀은 이를 통해 콜라보(CoLLaVO) 멀티모달 대형언어모델은 이미지 내에서 배경 및 물체를 구분하는 능력이 뛰어나 일차원적인 시각 구분 능력이 크게 향상됐다고 전했다.
AI MY뉴스 AI 추천


두 번째 대형언어모델인 '모아이(MoAI)'는 인간이 사물을 판단할 때 물체의 존재, 상태, 물체 간의 상호작용, 배경에 대한 이해, 텍스트에 대한 이해 등으로부터 상황을 판단하는 인지과학적인 요소에 영감을 받아서 만들었다는 게 연구팀의 설명이다.
기존 멀티모달 대형언어모델은 텍스트에 의미적으로 정렬된 시각 인코더(vision encoder)만을 사용한다. 이미지 픽셀 수준에서의 상세하고 종합적인 실세계 장면 이해가 부족하다는 점을 연구팀은 지적했다. 연구팀은 이런 컴퓨터 비전 모델들의 결과를 받으면 모두 인간이 이해할 수 있는 언어로 변환한 뒤에 멀티모달 대형언어모델에 입력으로 직접 사용했다.
노용만 교수는 "연구팀에서 개발한 공개형 멀티모달 대형언어모델이 허깅페이스 일간 화제의 논문(Huggingface Daily Papers)에 추천됐고, 각종 SNS를 통해 세계 연구자에게 알려지고 있다"며 "모든 모델을 공개형 대형언어모델로 출시 했기 때문에 이 연구모델이 멀티모달 대형언어모델 발전에 기여할 것"이라고 말했다.
biggerthanseoul@newspim.com