영상
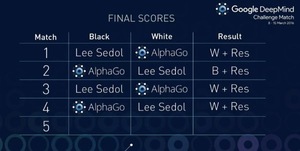
영상[뉴스핌=이수경 기자] 1국..2국..3국..이세돌 9단은 패배를 거듭할 때마다 동료 기사들과 밤새 복기를 하며 알파고의 바둑을 분석했고 결국 약점을 찾아냈다.
오늘(15일) 구글 인공지능 컴퓨터인 알파고(AlphaGo)와 이 9단이 마지막 대국을 앞둔 가운데 알파고가 자신이 패배했던 4국보다 '더 나은' 대국 실력을 보일 수 있을지 관심이 모아지고 있다. 알파고의 학습능력이 관심인 것이다.
전문가들은 컴퓨터의 경우 학습을 위해서는 방대한 데이터가 필요하기 때문에 이 9단과 4판을 두었다고 해서 알파고의 바둑지능이 올라가지는 않을 것이라고 봤다.

◆ 알파고, 정말 기계적 결함 드러냈나
지난 13일 대국에서는 이 9단이 허를 찌르는 '묘수'로 알파고를 상대로 기적적인 첫 승을 거머쥐었다. 업계 전문가들은 이 9단이 4번국 78번째 수에서 알파고가 학습하지 않은 창의적인 수를 두자, 알파고가 응수하는 데 어려움을 겪었다고 분석하기도 했다.
이를 두고 이 9단은 경기 직후 열리 기자 간담회에서 "(알파고가) 자기가 생각하지 못했던 수가 나왔을 때, 버그 형태의 수가 진행됐다"며 "생각 못 했을 때 대처 능력이 떨어졌다"며 말한 바 있다.
데미스 하사비스 딥마인드 대표는 자신의 SNS를 통해 79수 때 70%였던 승률이 87수 때는 50% 이하로 떨어졌다고 밝히기도 했다.
실제로 알파고가 지난 4국 경기에서 기계적인 결함을 드러냈다고 볼 수 있을까?
이에 대해 추형석 소프트웨어정책연구소 선임연구원은 "알파고의 학습 알고리즘이 잘못됐거나 그런 문제는 아니다"며 "계산상의 오차가 발생한 것일 뿐"이라고 일축했다.
계산할 시간만 충분하다면 사람이든, 인간이든 어떻게든 묘수를 찾는 데 성공한다는 설명이다. 그러나 바둑과 같은 게임에는 한정된 자원이 주어진다. 바로 '시간'이다. 제한시간 안에 가장 좋은 값을 찾는 것이 실력이다.
추 연구원은 "구글 알파고 이후에 2탄, 3탄 버전이 나오더라도 경우의 수를 100% 완벽하고 정확하게 계산할 수는 없을 것"이라며 "다만, 계산할 시간이 충분하면 좀 더 정확한 값을 찾는 것이고, 바둑처럼 제한시간이 있는 경우에는 그 시간 동안 탐색한 것 중 가장 좋은 값을 보여주는 것"이라고 말했다.
지난 4국 때와 마찬가지로 이 9단이 알파고가 전혀 예측하지 못한 수를 내놓으면 어떻게 될까? 상대방이 '착수'할 거라 예상하고 미리 계산해놓은 데이터들을 버리고 알파고는 재탐색(계산)을 한다. 그렇지만 알파고가 초읽기에 몰리지 않는 이상, 탐색할 여유는 많다. 이 9단이 예상외 수를 놓더라도 알파고가 여기에 대응할 수 있는 여건은 충분하다는 의미다.
◆ 스스로 진화하는 알파고의 '머신러닝'
데미스 하사비스 구글 딥마인드 CEO는 알파고가 머신러닝의 학습 알고리즘 중 하나인 심화학습(Deep Learning, 딥러닝)을 통해 스스로 학습한다고 설명한 바 있다.
'인공지능'이 인간과 같은 사고를 하는 컴퓨팅을 총칭한다면, '머신러닝'은 데이터를 분석하여 숨겨진 특성, 즉 패턴을 발견해 모델을 구축하는 학습 기술을 뜻한다. 더 나아가 경험으로부터 습득한 지식을 기반으로 스스로 성능을 향상시키는 과학이라고 볼 수도 있다.
'딥러닝'은 심화신경망을 활용하는 것이다. 사람의 뇌가 정보를 처리하는 것과 유사한 방식으로 다계층의 신경망 구조를 통해 스스로 특징값을 추출해 학습한다.
고속으로 학습하기 위해 알파고는 분산 컴퓨팅환경에서 최고의 성능을 냈다. 계산에 사용된 CPU는 1202개, GPU는 176개에 이른다. 그리고 딥러닝을 활용해 프로기사의 기보 16만개를 학습했다. 고작 5주만의 성과다.
구글은 아이디어(기보), 컴퓨팅자원(대용량 계산 및 분산 컴퓨팅)을 갖추고 딥러닝을 통해 알파고의 학습지능을 강화시킨 셈이다.

◆ "기계가 학습하려면 어느 정도 큰 규모의 데이터 필요"
지난 4국 대결 결과를 놓고 이세돌 9단이 2연승을 하지 않겠느냐는 조심스러운 관측도 나오고 있다. 알파고가 이 9단과의 4번의 경기를 치렀지만, 그 학습량이 충분하지 않고 하루 이틀 사이에 그 학습수준을 올리기에는 어렵다는 이유에서다.
장병탁 서울대학교 교수는 "딥러닝 기술을 활용한 알파고는 인간의 기보를 단순히 학습하는 것 뿐만 아니라 사람처럼 바둑을 두는 수준에 이르렀다"고 평가하면서도 "'하루’, '이틀’이라는 짧은 시간 안에 이 9단의 전략을 학습하는 데는 한계가 있다"고 평가한 바 있다.
추형석 연구원도 이 의견에 동의했다. 추 연구원은 "하루, 이틀 학습한다고 해서 알파고의 지능이 갑자기 높아지지는 않을 것"이라고 추측했다.
하사비스 CEO는 "기계가 학습하기 위해서는 어느 정도 큰 규모의 데이터가 필요하다"며 "인간은 한 사례만 가지고도 본인이 가진 다른 지식을 가지고 와서 쉽게 배우기 때문에 인간의 학습 효율성이 더 높다"고 말하기도 했다.
하지만 경기 결과는 한치 앞도 예측할 수 없는 상황이다. 알파고는 자신이 학습한 데이터에 대해서는 강한 자신감을 보인다. 4국때처럼 이 9단이 알파고가 학습하지 않은 '묘수'를 또다시 놓는다는 보장도 없다.
한 전문가는 "바둑의 경우의 수를 따졌을 때 오차 범위에 대해서는 인간이 기계를 따라갈 수 없다"며 "학습 데이터가 커지면 커질수록 정확도가 향상되는 만큼 마지막 경기 결과는 어떻게 될지 지켜봐야 할 것 같다"고 밝혔다.
[뉴스핌 Newspim] 이수경 기자 (sophie@newspim.com)